ainews-openai-beats-anthropic-to-releasing
OpenAI 抢在 Anthropic 之前发布了投机性解码。
提示词查找 (Prompt lookup) 和 投机性解码 (Speculative Decoding) 技术正日益受到关注,Cursor、Fireworks 已有相关实现,Anthropic 也预告了相关功能。OpenAI 利用这些方法实现了更快的响应速度和文件编辑,效率提升了约 50%。社区正积极探索这些技术进步在 AI 工程中的应用场景。
最近的动态展示了 NVIDIA、OpenAI、Anthropic、Microsoft、Boston Dynamics 和 Meta 等公司的进展。关键技术洞察涵盖了 CPU 推理能力、多模态检索增强生成 (RAG) 以及神经网络基础。新的 AI 产品包括完全由 AI 生成的游戏和先进的内容生成工具。此外,讨论还涉及了 AI 研究实验室面临的官僚主义和资源分配等挑战,以及 AI 安全和治理方面的担忧。
Prompt lookup is all you need.
2024年11月1日至11月4日的 AI 新闻。我们为您检查了 7 个 subreddit、433 个 Twitter 账号 和 30 个 Discord(216 个频道,7073 条消息)。预计为您节省阅读时间(以 200wpm 计算):766 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
自从最初的 Speculative Decoding 论文(以及像 Hydra 和 Medusa 这样的变体)发布以来,社区一直在竞相部署它。5 月,Cursor 和 Fireworks 宣布了他们超过 1000tok/s 的快速应用模型(我们的报道在此,Fireworks 的技术文章在此 —— 请注意,本期最初发布时曾有一个事实错误,称 Speculative Decoding API 尚未发布,正如这篇文章所解释的,Fireworks 在 5 个月前就发布了 Speculative Decoding API。)。8 月,Zed 预告了 Anthropic 的 新 Fast Edit 模式。但 Anthropic 的 API 尚未发布……这给 OpenAI 留下了大展身手的空间:
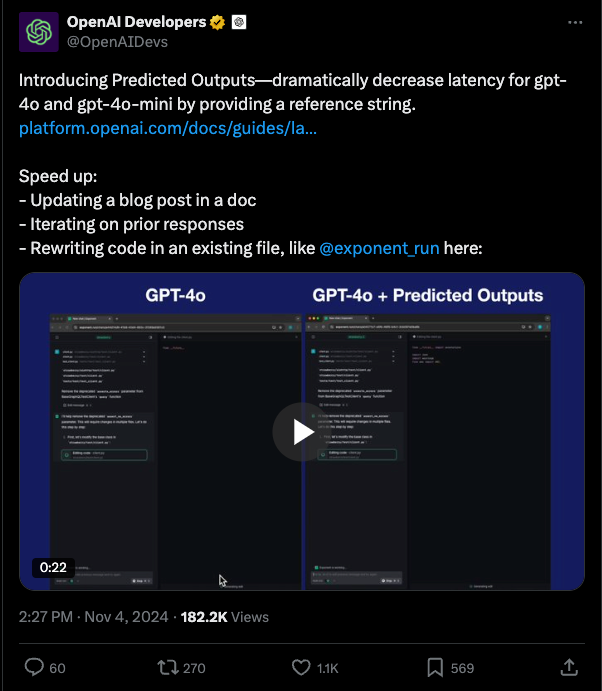
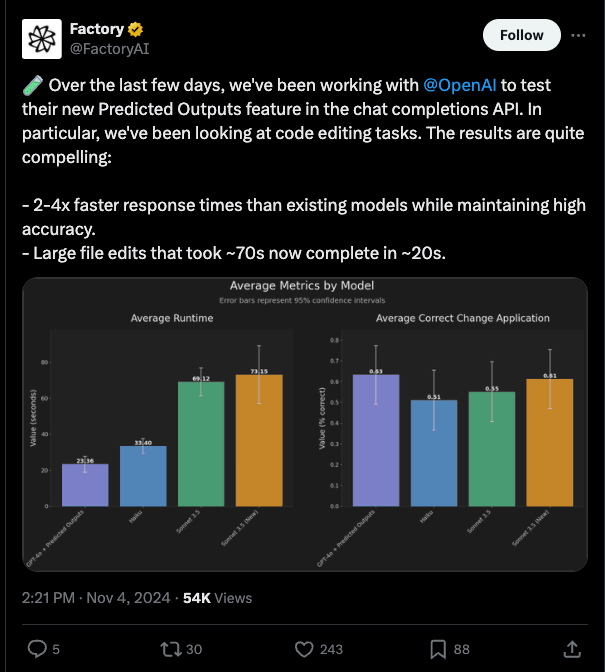
Factory AI 报告了更快的响应时间和文件编辑速度:
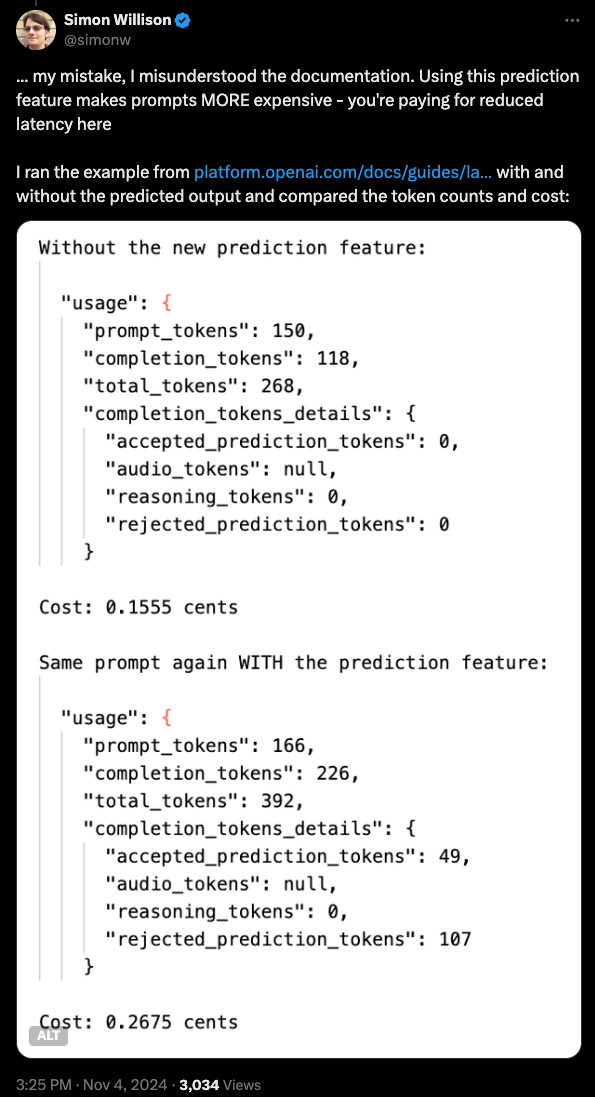
这种对 draft tokens 的额外处理成本有点模糊(取决于 32 个 token 的匹配情况),但你可以将 ~50% 作为一个不错的经验法则。
正如我们在本周的 Latent.Space 文章中所分析的,这很好地契合了为 AI Engineer 用例开发的丰富选项:

AI Twitter 综述
所有综述均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
AI 技术与行业动态
-
主要公司进展:@adcock_brett 强调了包括 Etched, Runway, Figure, NVIDIA, OpenAI, Anthropic, Microsoft, Boston Dynamics, ElevenLabs, Osmo, Physical Intelligence 和 Meta 在内的多家公司的重大进展。
- 模型与基础设施更新:
- @vikhyatk 宣布 CPU 推理功能现已支持本地运行。
- @dair_ai 分享了涵盖 MrT5, SimpleQA, Multimodal RAG 和 LLM 几何概念的顶级 ML 论文。
- @rasbt 发表了一篇文章,解释了 Multimodal LLMs 的两种主要方法。
- @LangChainAI 利用 NVIDIA 课程材料演示了结合 LLMs 的 RAG Agents。
- 产品发布与功能:
- @c_valenzuelab 讨论了除 Prompt 之外的新内容生成方式,包括 Advanced Camera Controls。
- @adcock_brett 报道了 Etched 和 DecartAI 的 Oasis,这是首款完全由 AI 生成的可玩 Minecraft 游戏。
- @bindureddy 展示了 AI Engineer 如何通过英文 Prompt 构建带有 RAG 的自定义 AI agents。
- 研究与技术洞察:
- @teortaxesTex 讨论了 LLMs 中专注于推理经济学(inference economics)的架构工作。
- @svpino 强调了理解基础知识的重要性:神经网络、损失函数、优化技术。
- @c_valenzuelab 详细说明了 AI 研究实验室在官僚主义和资源分配方面面临的挑战。
行业评论与文化
- 职业与发展:@c_valenzuelab 强调了 AI 研究实验室中的挫败感,包括官僚主义、审批延迟和资源分配问题。
- 技术讨论:@teortaxesTex 讨论了 AI 安全担忧及其对治理的影响。
- @DavidSHolz 通过一次《星际争霸》(Starcraft)游戏体验分享了一个有趣的 AI 安全类比。
幽默与梗
- @fchollet 调侃了 AGI 与滑动输入法准确度之间的对比。
- @svpino 评论了这款“蝴蝶应用”(指 Bluesky)的宁静特质。
- @vikhyatk 对 AI 访问和供应商发表了讽刺性评论。
AI Reddit 综述
/r/LocalLlama 综述
主题 1. Hertz-Dev:首个延迟仅为 120ms 的开源实时音频模型
-
🚀 分析了不同输入长度(从 5 到 200 个单词)下各种 TTS 模型的延迟! (评分: 114, 评论: 24):一项针对 text-to-speech (TTS) 模型的性能分析测量了 5 到 200 个单词输入下的 latency,结果显示 Coqui TTS 在短句(平均推理时间 0.8 秒)和长段落(2.1 秒)中始终优于其他模型。研究还发现,Microsoft Azure 和 Amazon Polly 的延迟随输入长度呈线性增长,而开源模型在超过 100 个单词 的输入时表现出更不稳定的性能模式。
-
Hertz-Dev:一个开源的 8.5B 音频模型,用于实时对话式 AI,在单张 RTX 4090 上具有 80ms 理论延迟和 120ms 实际延迟 (Score: 591, Comments: 78):Hertz-Dev 是一个开源的 8.5B 参数音频模型,在单张 RTX 4090 GPU 上运行,实现了 120ms 的实际延迟和 80ms 的理论延迟,适用于对话式 AI。该模型似乎是为实时音频处理而设计的,尽管帖子中未提供具体的实现细节或基准测试方法。
- Hertz 的 70B 参数版本目前正在训练中,并计划扩展到更多模态。运行这个更大的模型可能需要 H100 GPUs,不过有人建议量化(quantization)可能有助于降低硬件需求。
- 围绕开源状态展开了讨论,用户注意到该模型仅发布了权重和推理代码(类似于 Llama、Gemma、Mistral)。完全开源模型的显著例外包括 Olmo 和 AMD 的 1B 模型。
- 该模型具有 17 分钟的上下文窗口,理论上可以像其他 Transformer 一样使用音频数据集进行微调。其实际延迟(120ms)优于 GPT-4o(平均 320ms),并接近人类对话间隔(200-250ms)。
{kind=link}
主题 2. 语音克隆进展:F5-TTS vs RVC vs XTTS2
-
在 Linux 上通过按键与本地 LLM 对话。语音转文字到任何窗口,适用于大多数桌面环境。两个热键即是 UI。 (Score: 51, Comments: 1):BlahST 工具使 Linux 用户能够使用热键执行本地语音转文字和 LLM 交互,利用了 whisper.cpp、llama.cpp(或 llamafile)和 Piper TTS,无需 Python 或 JavaScript。在配备 Ryzen CPU 和 RTX3060 GPU 的系统上运行,该工具使用 gemma-9b-Q6 模型可达到 ~34 tokens/秒,并实现 90 倍实时语音推理,同时保持较低的系统资源占用,并支持包括中文翻译在内的多语言能力。
-
如果有大量参考音频,最好的开源语音克隆方案是什么? (Score: 71, Comments: 18):对于每个角色拥有 10-20 分钟参考音频的语音克隆,作者正在寻找 ElevenLabs 和 F5-TTS 的替代方案用于自托管部署。该帖子特别要求能够针对单个角色预训练模型以便后续推理的解决方案,摆脱像 F5-TTS 这种针对极少参考音频优化的少样本学习(few-shot learning)方法。
- RVC (Retrieval-based Voice Conversion) 表现良好,但需要输入音频进行转换。当与 XTTS-2 结合使用时,由于 TTS 伪影,结果可能参差不齐,不过使用 alltalk-tts beta 可以简化这一过程。
- 微调 F5-TTS 使用 lpscr 的实现 产生了高质量的结果且推理速度快,达到了与 ElevenLabs 相当的质量。该过程现在已通过
f5-tts_finetune-gradio命令集成到主仓库中。 - GPT-SoVITS、MaskCGT 和 OpenVoice 被提及为强有力的替代方案。MaskCGT 在零样本(zero-shot)性能上领先,而 GPT-SoVITS 被认为超越了微调后的 XTTS2 或 F5 参考语音克隆。
主题 3. Token 管理与模型优化技术
-
[小型模型 (<5B) 的 MMLU-Pro 评分] (https://i.redd.it/dbqap2z19nyd1.jpeg) (Score: 166, Comments: 49):MMLU-Pro 基准测试每个问题有 10 个多选题选项,为随机猜测设定了 10% 的基准分数。该测试评估了 5B 参数以下语言模型的性能。
-
tips for dealing with unused tokens? keeps getting clogged (Score: 150, Comments: 29): LLM 中的 Token usage optimization 需要同时管理输入和输出 Token,以防止内存阻塞和处理效率低下。该帖子似乎在寻求建议,但缺乏关于所遇到的未使用 Token 具体问题或所使用的 LLM 系统的详细信息。
Theme 4. MG²: New Melody-First Music Generation Architecture
- MG²: Melody Is All You Need For Music Generation (Score: 57, Comments: 9): MG² 是一个在 500,000 个样本数据集上训练的新型 music generation model,它专注于旋律生成,而忽略了和声和节奏等其他音乐元素。该模型证明了旋律本身就包含足够的高质量音乐生成信息,挑战了整合多种音乐组件的传统方法,并在使用显著更少参数的情况下实现了与更复杂模型相当的效果。该研究引入了一种专门为旋律处理设计的创新 self-attention mechanism,使模型能够捕捉音乐序列中的长程依赖关系,同时保持计算效率。
- MusicSet dataset 现已在 HuggingFace 上发布,包含 500k 个样本的高质量音乐波形,并附带描述和独特的旋律。用户对该数据集的发布表示热烈欢迎,认为其推动了音乐生成研究。
- 多位用户发现该模型的示例输出不尽如人意,特别是对缺乏旋律输入功能的担忧。一位用户特别希望能将哼唱的旋律转化为电影质感的乐曲。
- 关于电子游戏音乐生成的讨论突出了对创作类似于《洛克人》(Mega Man)和《大金刚国度》(Donkey Kong Country)等经典原声带的兴趣,并提到 Suno 是目前考虑版权问题的游戏音乐生成解决方案。
其他 AI Subreddit 回顾
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI 模型性能与基准测试
- SimpleBench 揭示了人类与 AI 推理之间的差距:人类基准达到 83.7%,而顶级模型如 o1-preview (41.7%) 和 3.6 Sonnet (41.4%) 在基础推理任务中表现挣扎,突显了在时空推理(spatial-temporal reasoning)和社交智能(social intelligence)方面的局限性 /r/singularity。
- 关键评论指出,模型从语言中获取对世界的理解,而人类是在已习得的世界模型(world models)之上构建语言。
AI 安全与基础设施
- Nvidia GeForce GPU 存在严重安全漏洞:由于发现安全缺陷,敦促所有 Nvidia GeForce GPU 用户立即更新驱动程序 /r/StableDiffusion。
AI 图像生成进展
- FLUX.1-schnell 模型发布,提供免费无限次生成:新网站上线,提供对 FLUX.1-schnell 图像生成能力的无限制访问 /r/StableDiffusion。
- AI 图像生成的历史进展:视觉对比展示了从 2015 年到 2024 年 AI 图像生成的巨大进步,并详细讨论了从早期的 DeepDream 到现代模型的演变 /r/singularity。
AI 伦理与社会
- Yuval Noah Harari 警告 AI 驱动的现实扭曲:讨论 AI 创建沉浸式但可能具有欺骗性的数字环境对社会的潜在影响 /r/singularity。
迷因与幽默
- AI 生成的写实动漫:高赞帖子(942 分)展示了写实动漫风格的 AI 生成作品 /r/StableDiffusion。
- AI 安保摄像头幽默:一段关于南非安保摄像头系统的视频 /r/singularity。
AI Discord 摘要回顾
由 O1-preview 生成的摘要之摘要的摘要
主题 1. 重大 LLM 发布与模型更新
- Claude 3.5 Haiku 强势发布:Anthropic 发布了 Claude 3.5 Haiku,虽然各项基准测试表现更佳,但其 4 倍的价格涨幅让用户措手不及。社区正在争论性能的提升是否足以支撑其成本的增加。
- OpenAI 的 O1 模型现身又消失:用户曾通过调整 URL 短暂访问到了神秘的 O1 模型,并在 OpenAI 关闭入口前体验了其高级功能。关于该模型的能力和正式发布计划的猜测层出不穷。
- 免费 Llama 3.2 模型亮相 OpenRouter:OpenRouter 现在提供对 Llama 3.2 模型的免费访问,包括速度大幅提升的 11B 和 90B 变体。用户对 11B 变体达到 900 tps 的表现感到兴奋。
主题 2. AI 在安全与医疗领域的进展
- Llama 3.1 在黑客基准测试中胜过 GPT-4o:新的 PentestGPT 基准测试显示,Llama 3.1 在自动化渗透测试中的表现优于 GPT-4o。不过,这两个模型在网络安全应用方面仍有改进空间。
- Google 的 MDAgents 旨在优化医疗决策:Google 推出了 MDAgents,这是一种 LLM 的自适应协作机制,旨在增强医疗决策能力。像 UltraMedical 和 FEDKIM 这样的模型有望彻底改变医疗 AI 领域。
- Aloe Beta 作为开源医疗 LLM 萌芽:使用 axolotl 进行微调的 Aloe Beta 带来了一系列开源医疗 LLM。这标志着 AI 驱动的医疗解决方案取得了重大进展。
主题 3. LLM 微调与性能挑战
- Unsloth AI 开启微调极速模式:Unsloth AI 使用 LoRA 将模型微调速度提升了近 2 倍,并大幅降低了 VRAM 占用。用户们正在分享高效优化模型的策略。
- Hermes 405b 步履蹒跚,其他模型全速冲刺:Hermes 405b 用户反映响应时间极慢且频繁报错,引发了不满。在用户寻找替代方案的同时,关于速率限制(rate limiting)和 API 问题的猜测不断。
- LM Studio 的混合 GPU 支持喜忧参半:LM Studio 支持 AMD 和 Nvidia GPU 混合配置,但由于依赖 Vulkan,性能受到了影响。为了获得最佳效果,建议仍使用型号一致的 GPU。
主题 4. AI 进军游戏与创意领域
- Oasis 游戏开启 AI 世界新前沿:Oasis 是首款完全由 AI 生成的游戏,允许玩家探索实时交互环境。这里没有传统游戏引擎——只有纯粹的 AI 魔法。
- Open Interpreter 为 AI 爱好者带来惊喜:随着用户将其与 Screenpipe 等工具集成以处理 AI 任务,Open Interpreter 广受欢迎。语音功能和本地录制提升了用户体验。
- AI 播客遭遇杂音,用户要求更好的音质:NotebookLM 用户反映 AI 生成的播客存在质量问题,包括随机中断和奇怪的杂音。要求强化音频处理和提升稳定性的呼声日益高涨。
主题 5. AI 伦理、审查与社区声音
- 越狱者争论 LLM 的真正自由:用户质疑“越狱” LLM 究竟是真正解放了模型,还是仅仅增加了更多约束。社区深入探讨了越狱背后的动机和机制。
- 过度审查让模型失声:Phi-3.5 严重的审查机制令用户感到沮丧,导致出现了幽默的模拟回复以及对模型进行“去审查”的尝试。一个无审查版本已出现在 Hugging Face 上。
- AI 搜索引擎竞争激烈,用户仍在寻找最优选:OpenAI 新推出的 SearchGPT 在实时结果方面表现平平,而 Perplexity 等替代方案则赢得了赞誉。AI 搜索大战正在升温,但并非所有用户都对此买账。
第一部分:Discord 高层级摘要
HuggingFace Discord
-
LLM 微调与性能增强:Neuralink 在其代码性能上实现了 2倍加速,在 980 FLOPs 下达到了 tp=2;同时,根据 渗透测试基准测试论文 的详细说明,Llama 3.1 在使用 PentestGPT 工具时表现优于 GPT-4o。
- 此外,Gemma 2B 在特定任务上以更低的 VRAM 占用 超越了 T5xxl,讨论中还强调了由于 弃用问题 (deprecation issues) 导致的 MAE 微调 挑战。
-
AI 驱动的网络安全模型与基准测试:一项新的基准测试 PentestGPT 显示,Llama 3.1 在自动化渗透测试中优于 GPT-4o。根据 最近的研究,这表明两种模型在网络安全应用中仍需改进。
- 社区成员对开发用于 恶意软件检测 (malware detection) 的 AI 模型表现出日益增长的兴趣,并寻求实施策略方面的指导。
-
AI 开发工具与环境:VividNode v1.6.0 的发布引入了对 edge-tts 的支持,并通过 GPT4Free 增强了图像生成能力,同时推出了兼容 Ubuntu 和 Apple Silicon macOS 的新 ROS2 Docker 环境。
- GitHub 仓库 中讨论的 ShellCheck(一种用于 shell 脚本的静态分析工具)也被强调用于提高脚本的可靠性。
-
量子计算在 AI 领域的进展:研究人员展示了 $^{173}$Yb 原子中薛定谔猫态(Schrödinger-cat state)长达 1400 秒 的相干时间,标志着 arXiv 论文 中讨论的 量子计量学 (quantum metrology) 取得了重大突破。
- 此外,据 Nature Photonics 报道,一种新型 磁光存储芯片 (magneto-optic memory chip) 设计有望降低 AI 计算的能耗。
-
AI 在医疗决策中的应用:Google 推出了 MDAgents,这是一种用于增强 医疗决策 的 LLMs 自适应协作方案,包含 UltraMedical 和 FEDKIM 等模型,详见最近的 Medical AI 帖子。
- 这些创新旨在通过先进的 AI 模型简化医疗流程并提高诊断准确性。
Unsloth AI (Daniel Han) Discord
-
Unsloth AI 加速模型微调:Unsloth AI 项目通过利用 LoRA,使用户微调 Mistral 和 Llama 等模型速度提升近 2倍,并显著降低了 VRAM 消耗。
- 用户讨论了在扩展规模之前迭代优化较小模型的策略,并强调了数据集大小和质量对于有效训练的重要性。
-
Python 3.11 提升跨操作系统性能:升级到 Python 3.11 可以带来性能提升,在 Linux 上提供约 1.25 倍的速度,在 Mac 上为 1.2 倍,在 Windows 系统上为 1.12 倍,如 推文 所述。
- 讨论中也提出了对 Python 升级期间包兼容性的担忧,强调了维护软件稳定性所涉及的复杂性。
-
通过量化实现高效模型推理:讨论集中在微调 Qwen 2.5 72b 等量化模型的可行性,旨在降低内存占用并在 CPUs 上获得满意的推理速度。
- 会议指出,虽然 模型量化 (model quantization) 有助于轻量化部署,但初始训练仍需要大量的计算资源。
-
用于 LLM 集成的最佳 Web 框架:对于将语言模型集成到 Web 应用程序中的建议包括用于前端开发的 React 和 Svelte 框架。
- 对于倾向于使用基于 Python 解决方案来构建模型界面的开发者,建议使用 Flask。
-
增强 Unsloth 仓库的 Git 实践:讨论中强调了 Unsloth 仓库中缺少 .gitignore 文件的问题,强调了在推送更改之前管理文件的重要性。
- 用户分享了通过有效使用 git 命令和本地排除配置来保持干净 git 历史记录的见解。
OpenRouter (Alex Atallah) Discord
-
Claude 3.5 Haiku 三版本齐发:Anthropic 发布了 Claude 3.5 Haiku 的标准版、自我审查版(self-moderated)和带日期版本。在 Claude 3.5 Overview 了解更多版本信息。
- 用户可以通过 standard、dated 和 beta releases 访问不同变体,方便进行无缝更新和测试。
-
免费 Llama 3.2 模型现已上线:Llama 3.2 模型可通过 OpenRouter 免费使用,包含 11B 和 90B 变体,且速度有所提升。访问地址:11B variant 和 90B variant。
- 11B 变体的性能达到 900 tps,而 90B 变体提供 280 tps,满足多样化的应用需求。
-
Hermes 405b 遭遇延迟问题:Hermes 405b 的免费版本正面临严重的延迟和访问错误。
- 推测这些问题可能是由于速率限制(rate limiting)或临时停机造成的,尽管部分用户仍能间歇性地收到响应。
-
API 速率限制引发用户困惑:用户在 ChatGPT-4o-latest 等模型上触及速率限制,导致对 OpenRouter 上 GPT-4o 和 ChatGPT-4o 版本的区别产生困惑。
- 模型名称之间的区分不明确,导致了用户体验参差不齐,以及对速率限制政策的不确定性。
-
Haiku 定价上涨引发担忧:Claude 3.5 Haiku 的定价大幅上涨,引发了用户群对其负担能力的担忧。
- 用户对成本增加感到沮丧,尤其是将 Haiku 与 Gemini Flash 等替代方案进行比较时,对其未来的可行性提出了质疑。
LM Studio Discord
-
LM Studio 支持混合 GPU:用户确认 LM Studio 支持 AMD 和 Nvidia GPU 混合使用,但由于依赖 Vulkan,性能可能会受到限制。
- 为了获得最佳效果,建议使用相同的 Nvidia 显卡,而非混合 GPU 配置。
-
LM Studio 中的 Embedding 模型限制:并非所有模型都适用于 Embedding;具体而言,Gemma 2 9B 在 LM Studio 中不兼容此用途。
- 建议用户选择合适的 Embedding 模型以防止运行时错误。
-
LLM 结构化输出挑战:用户在强制执行结构化输出格式时遇到困难,导致出现多余文本。
- 建议包括加强 Prompt Engineering 以及利用 Pydantic 类来提高输出精度。
-
使用 Python 进行 LLM 集成:讨论集中在实现代码片段以构建自定义 UI,并集成来自 Hugging Face 的各种语言模型功能。
- 参与者强调了交替使用多个模型来处理不同任务的灵活性。
-
LM Studio 在不同硬件上的性能表现:用户报告了在不同硬件配置下通过 LM Studio 运行 LLM 的各项性能指标,部分用户遇到了 Token 生成延迟。
- 用户对上下文管理(context management)和硬件限制导致这些性能问题的担忧有所增加。
Nous Research AI Discord
-
Hermes 405b 模型性能:用户报告通过 Lambda 和 OpenRouter 使用 Hermes 405b 模型时响应时间缓慢且出现间歇性错误,一些人甚至形容其性能“慢如冰川”。
- Lambda 上的免费 API 特别表现出不稳定的可用性,导致尝试访问该模型的用户感到沮丧。
-
越狱 LLM:一位成员质疑越狱 LLM 是否更多是为了通过创建约束来释放它们,这引发了关于此类行为的动机和影响的热烈讨论。
- 一位参与者强调,许多擅长越狱的人可能并不完全理解 LLM 底层的运行机制。
-
MDAgents:Google 推出了 MDAgents,展示了一种旨在增强医疗决策的 LLM 自适应协作 (Adaptive Collaboration of LLMs)。
- 本周总结该论文的播客强调了模型协作在应对复杂医疗挑战中的重要性。
-
Nous Research 模型的未来:Teknium 表示 Nous Research 不会创建任何闭源模型,但针对某些特定用例的其他产品可能会保持私有或基于合同。
- Hermes 系列将始终保持开源,确保其开发的透明度。
-
AI 搜索引擎性能:用户感叹 OpenAI 的新搜索未能提供实时结果,特别是与 Bing 和 Google 等平台相比。
- 有人指出 Perplexity 在搜索结果质量方面表现出色,被认为优于 Bing 和 OpenAI 的产品。
Perplexity AI Discord
-
Claude 3.5 Haiku 丰富 AI 选择:Claude 3.5 Haiku 在 Amazon Bedrock 和 Google 的 Vertex AI 等平台上线,其新的定价结构引起了用户的担忧。
- 尽管成本增加,Claude 3.5 Haiku 仍保持了强大的对话能力,但其相对于现有工具的价值主张仍存争议。
-
SearchGPT:OpenAI 对传统搜索的回击:SearchGPT 的推出提供了一系列新的 AI 驱动搜索功能,旨在与成熟的搜索引擎竞争。
- 此次发布引发了关于 AI 在信息检索中不断演变的角色以及搜索技术未来动态的讨论。
-
中国 Llama AI 模型推进军事 AI:报告显示中国军方正在开发基于 Llama 的 AI 模型,这标志着国防 AI 应用的战略举措。
- 这一进展加剧了全球关于 AI 在军事进步中的作用以及国防领域国际技术竞争的讨论。
Eleuther Discord
-
梯度对偶化(Gradient Dualization)影响模型训练动力学:讨论强调了梯度对偶化在训练深度学习模型中的作用,重点关注随着架构规模扩大,范数(norms)如何影响模型性能。
- 参与者探讨了在并行和串行注意力机制之间交替的影响,引用了论文 Preconditioned Spectral Descent for Deep Learning。
-
优化器参数微调反映了 Adafactor 调度:成员们分析了 Adafactor 调度的变化,指出其与增加另一个超参数的相似性,并质疑这些调整背后的创新性。
- 正如 Quasi-hyperbolic momentum and Adam for deep learning 中所讨论的,最佳的 beta2 调度被发现与 Adafactor 现有的配置相似。
-
配置 GPT-NeoX 的最佳实践:工程师们正在使用 Hypster 进行配置,并在其 GPT-NeoX 设置中集成 MLFlow 进行实验跟踪。
- 一位成员询问了同时使用 DagsHub、MLFlow 和 Hydra 的普遍性,并引用了 lm-evaluation-harness。
-
DINOv2 通过扩展数据增强 ImageNet 预训练:DINOv2 利用了 22k ImageNet 数据,与之前的 1k 数据集相比,提升了评估指标。
- DINOv2 论文 展示了增强的性能指标,强调了有效的蒸馏技术。
-
神经网络中规模(Scaling)与深度(Depth)之间的权衡:社区讨论了神经网络架构中深度与宽度之间的平衡,分析了每个维度如何影响整体性能。
- 建议进行实证验证,以证实随着模型规模扩大,网络深度与宽度之间的动力学变得越来越一致的理论。
aider (Paul Gauthier) Discord
-
Claude 3.5 Haiku 在排行榜上取得进展:Claude 3.5 Haiku 在 Aider’s Code Editing Leaderboard 上获得了 75% 的评分,排名紧随之前的 Sonnet 06/20 模型之后。
- 这标志着 Haiku 成为一种具有成本效益的替代方案,在代码编辑任务中与 Sonnet 的能力非常接近。
-
Aider v0.62.0 集成 Claude 3.5 Haiku:最新的 Aider v0.62.0 版本现已全面支持 Claude 3.5 Haiku,可通过
--haiku标志激活。- 此外,它还引入了应用来自 ChatGPT 等 Web 应用程序编辑的功能,增强了开发者的工作流。
-
全面的 AI 模型对比:讨论强调了 Sonnet 3.5 的卓越质量,而 Haiku 3.5 被认为是一个强力但速度较慢的竞争者。
- 社区成员比较了各模型的编码能力,并分享了实际应用经验。
-
基准测试性能洞察:在 Paul G 分享的基准测试结果中,Sonnet 3.5 的表现优于其他模型,而 Haiku 3.5 在效率上稍逊一筹。
- 用户对混合模型组合(如 Sonnet 和 Haiku)在处理多样化任务时的表现表现出浓厚兴趣。
-
OpenAI 战略性的 o1 泄露:用户观察到 OpenAI 泄露 o1 似乎是故意的,旨在为未来的发布制造期待。
- 引用了 Sam Altman 过去的策略,如使用 strawberries(草莓)和 Orion(猎户座星空)等意象来引发关注。
OpenAI Discord
-
GPT-4o 通过 Canvas 功能增强推理能力:GPT-4o 的下一个版本正在推出,引入了类似于 O1 的高级推理能力。此次更新包括将大文本块放入画布风格框 (canvas-style box)等功能,增强了推理任务的可用性。
- 用户在获得 O1 的完整访问权限后表达了兴奋之情,并指出推理效率有了显著提高。此次升级旨在为 AI Engineers 简化复杂任务的执行。
-
OpenAI 的 Orion 项目引发期待:OpenAI 的 Orion 项目让成员们对预计在 2025 年推出的 AI 创新感到兴奋。讨论强调,虽然 Orion 正在进行中,但目前的 O1 等模型尚未被归类为真正的 AGI。
- 对话强调了 Orion 项目的潜力,即弥合当前能力与 AGI 之间的差距,成员们热切期待在不久的将来取得重大突破。
-
在 OpenAI 集成中采用中间件:成员们正在探索使用中间件产品,将请求路由到不同的端点,而不是直接连接到 OpenAI。这种方法正在被讨论,以评估其规范性和有效性。
- 一位成员询问使用中间件是否为标准模式,寻求社区关于将 API endpoints 与 OpenAI 服务集成的最佳实践见解。
-
使用分析工具增强 Prompt 测量:讨论集中在用于跟踪用户交互(包括挫败感水平和任务完成率)的 Prompt 测量工具上。成员们建议利用情感分析来获得更深入的见解。
- 实施者正在考虑引导 LLMs 处理对话数据,旨在通过数据驱动的调整来优化 Prompt 有效性并提高整体用户满意度。
-
使用 LLMs 自动化任务规划:参与者正在寻求使用 LLMs 自动化复杂任务规划的资源,特别是用于生成 SQL queries 和进行数据分析。为了实现有效的自动化,强调了需求清晰度的重要性。
- 贡献者强调了模型在协助头脑风暴会议和简化规划流程方面的潜力,并强调了精确查询制定的重要性。
Notebook LM Discord Discord
-
NotebookLM 语言配置挑战:用户报告了在配置 NotebookLM 以其首选语言响应时遇到困难,尤其是在上传不同语言的文档时。说明强调 NotebookLM 默认为用户 Google account 中设置的语言。
- 这引发了关于增强语言支持以适应更多样化用户群的讨论。
-
Podcast 生成质量问题:多位用户指出了对 NotebookLM Podcast 质量的担忧,注意到播放过程中出现意外中断和随机声音。虽然有些人觉得这些中断很有趣,但其他人对收听体验的负面影响表示沮丧。
- 这些质量问题导致了对更强大的音频处理和稳定性改进的呼吁。
-
API 开发推测:围绕 NotebookLM 的 API 潜在开发展开了讨论,这受到 Vicente Silveira 的一条推文的影响,该推文暗示了即将推出的 API 功能。
- 尽管社区对此很感兴趣,但尚未发布官方公告,这为基于行业趋势的推测留下了空间。
-
音频概览功能请求:一位用户询问如何使用 NotebookLM 从一份 200 页的密集 PDF 中生成多个音频概览,并考虑将文档拆分为较小部分的劳动密集型方法。建议包括提交从单一来源生成音频概览的功能请求。
- 这反映了对 NotebookLM 中更高效摘要工具的需求,以便无缝处理大型文档。
-
特殊教育需求用例扩展:成员们分享了为特殊需求学生使用 NotebookLM 的经验,并寻求用例或成功案例,以支持向 Google 的 accessibility team(无障碍团队)进行推介。还讨论了在英国建立集体的计划。
- 这些努力凸显了社区利用 NotebookLM 增强教育无障碍性的倡议。
GPU MODE Discord
-
Triton Kernel Optimization:成员们讨论了优化 Triton kernels 的复杂性,特别是 GPU 等待 CPU 操作的时间,并建议堆叠多个 Triton matmul 操作可以减少大矩阵的开销。
- 对话强调了通过最小化 CPU-GPU 同步延迟来提高性能的策略,成员们考虑了多种增强 kernel 效率的方法。
-
FP8 Quantization Techniques:一位用户分享了他们在 FP8 quantization 方法方面的经验,指出与纯 PyTorch 实现相比,速度提升令人惊讶,并提供了其 GitHub repository 的链接。
- 讨论强调了高效动态量化 activations 的挑战,并引用了 flux-fp8-api 作为实现这些技术的资源。
-
LLM Inference on ARM CPUs:探索了在 NVIDIA Grace 和 AWS Graviton 等 ARM CPU 上进行 LLM inference,讨论了处理高达 70B 的大型模型,并参考了 torchchat repository。
- 参与者指出,将多个配备 Ampere Altra 处理器的 ARM SBCs 进行集群可以产生有效的性能,特别是在利用 tensor parallelism 来桥接 CPU 和 GPU 能力时。
-
PyTorch H100 Optimizations:深入讨论了 PyTorch 针对 H100 硬件的优化,确认支持 cudnn attention,但指出由于一些问题,在 2.5 版本中默认禁用了该功能。
- 成员们分享了关于 H100 特性稳定性的不同经验,提到 Flash Attention 3 仍处于开发阶段,影响了性能的一致性。
-
vLLM Demos and Llama 70B Performance:宣布了开发展示带有自定义 kernels 的 vLLM 实现的 streams and blogs 计划,并考虑创建一个 fork 仓库来增强 forward pass。
- 关于提高 Llama 70B 在高解码负载下性能的讨论包括与 vLLM maintainers 的潜在合作,以及集成 Flash Attention 3 以获得更好的效率。
Latent Space Discord
-
Claude Introduces Visual PDF Support:Claude 在 Claude AI 和 Anthropic API 中推出了 visual PDF support,使用户能够分析各种文档格式。
- 此更新允许从财务报告和法律文件中提取数据,显著增强了 user interactions。
-
AI Search Engine Competition Intensifies:随着 SearchGPT 和 Gemini 等新进入者挑战 Google 的主导地位,搜索引擎竞争的复苏显而易见。
- AI Search Wars 文章 详细介绍了各种创新的搜索解决方案及其影响。
-
O1 Model Briefly Accessible, Then Secured:O1 model 曾一度可以通过修改 URL 访问,支持图像上传和快速 inference 能力。
- 在兴奋和猜测中, ChatGPT 的 O1 出现了,但此后访问受到了限制。
-
Entropix Achieves 7% Boost in Benchmarks:Entropix 展示了小模型在 benchmarks 中提升了 7 个百分点,表明了其可扩展性。
- 成员们正期待这些结果将如何影响未来的 model developments 和实现。
-
Open Interpreter Gains Traction Among Users:用户对 Open Interpreter 表现出极大的热情,考虑将其集成到 AI 任务中。
- 一位成员建议将其设置好以备将来使用,并提到他们觉得自己 out of the loop。
Stability.ai (Stable Diffusion) Discord
- A1111 对 Stable Diffusion 3.5 的支持:用户讨论了 Stable Diffusion 3.5 是否能在 AUTOMATIC1111 上运行,提到虽然它是新发布的,但目前的兼容性可能有限。
- 有人建议在 YouTube 上查找有关利用 SD3.5 的指南,因为其最近刚刚发布。
- 对服务器中诈骗机器人的担忧:用户对发送链接的诈骗机器人以及服务器内缺乏直接的审核人员(moderation)表示担忧。
- 讨论了右键报告等审核方法,但对其防止垃圾信息的有效性看法不一。
- 提示词“飘动的头发”的技巧:一位用户寻求关于如何编写“waving hair”(飘动的头发)的提示词,而又不让 AI 误以为角色在“waving”(挥手)的建议。
- 建议包括使用更简单的词汇如“wavey”来实现预期效果,以避免误解。
- 模型训练资源:用户分享了使用图像和标签训练模型的见解,并对旧教程的参考价值表示不确定。
- 提到的资源包括 KohyaSS,并讨论了高效的训练方法和工具。
- Dynamic Prompts 扩展的问题:一位用户报告在 AUTOMATIC1111 中使用 Dynamic Prompts 扩展时频繁崩溃,感到非常沮丧。
- 对话集中在安装错误和故障排除协助上,一位用户分享了他们的经验。
Modular (Mojo 🔥) Discord
-
Mojo 硬件下放(Hardware Lowering)支持:成员们讨论了 Mojo 当前硬件下放能力的局限性,特别是无法按照 [Mojo🔥 FAQ Modular Docs](https://docs.modular.com/mojo/faq#how-does-mojo-support-hardware-lowering.) 中所述将中间表示(intermediate representations)传递给外部编译器。 - 建议如果需要增强硬件支持,可以 联系 Modular 以寻求潜在的 upstreaming 选项。
- 在 Mojo 中管理引用:一位成员询问关于在容器之间存储安全引用的问题,并遇到了 struct 中生命周期(lifetimes)的问题,强调了需要量身定制设计以避免失效问题。
- 讨论强调了在操作自定义数据结构中的元素时,确保指针稳定性(pointer stability)的重要性。
- Slab List 实现:成员们审查了 slab list 的实现并考虑了内存管理方面,指出将其功能与标准集合(standard collections)合并的可能性。
- 使用内联数组(inline arrays)的概念及其对性能和内存一致性的影响对他们的设计至关重要。
- Mojo 稳定性与 Nightly 版本:对于完全切换到 Mojo Nightly 版本的稳定性存在担忧,强调了 Nightly 版本在合并到 main 分支之前可能会发生重大变化。
- 尽管 Nightly 版本包含最新进展,成员们仍强调了稳定性的必要性,并对重大变更发布了公告(PSA)。
- 神经网络中的自定义 Tensor 结构:探讨了在神经网络中自定义 tensor 实现的需求,揭示了诸如内存效率和设备分布等各种用例。
- 成员们指出了这与数据结构选择的相似之处,认为对专门化数据处理的需求仍然具有现实意义。
Interconnects (Nathan Lambert) Discord
- AMD 重新推出 OLMo 语言模型:AMD 重新推出了 OLMo 语言模型,在 AI 社区引起了极大关注。
- 成员们反应中带着怀疑和幽默,对 AMD 在语言建模领域的进展表示惊讶。
- Grok 模型 API 发布,支持 128k 上下文:Grok 模型 API 已发布,为开发者提供具有 128,000 token 上下文长度的模型访问权限。
- Beta 计划包含免费试用额度,被幽默地称为“25 自由币(freedom bucks)”,旨在鼓励开发者进行尝试。
- Claude 3.5 Haiku 价格翻四倍:Claude 3.5 Haiku 已发布,虽然基准测试表现有所提升,但其成本是前代产品的 4 倍。
- 在市场压力推动 AI 推理成本下降的背景下,这种出人意料的价格上涨引发了种种猜测。
- 探索 AnthropicAI Token 计数 API:成员们尝试了 AnthropicAI Token Counting API,重点关注 Claude 的聊天模板以及图像/PDF 的数字 Token 化。
- 随附的图片提供了该 API 能力的摘要(TL;DR),突出了其处理不同数据格式的能力。
- 中国军方利用 Llama 模型获取战争见解:中国军方利用 Meta 的 Llama 模型分析并开发战争策略和架构,并使用公开的军事数据对其进行了微调。
- 这种适配使该模型能够有效回答与军事事务相关的查询,展示了 Llama 的多功能性。
LlamaIndex Discord
- OilyRAGs 凭借 AI 夺得黑客松大奖:AI 驱动的目录 OilyRAGs 在 LlamaIndex 黑客松中获得第三名,展示了 Retrieval-Augmented Generation (RAG) 在增强机械工作流方面的能力。点击此处了解其实现方式,据称其效率提升了 6000%。
- 该项目旨在简化机械领域的任务,展示了 RAG 的实际应用。
- 优化自定义 Agent 工作流:关于自定义 Agent 创建的讨论建议绕过 Agent worker/runner,转而使用 Workflows,详见文档。
- 这种方法简化了 Agent 开发过程,能够更高效地集成专门的推理循环。
- RAG 流水线的成本估算策略:成员们讨论了使用 OpenAIAgentRunner 进行 RAG 流水线成本估算,并明确了工具调用(tool calls)与补全调用(completion calls)是分开计费的。
- 他们强调使用 LlamaIndex 的 Token 计数工具来准确计算每条消息的平均 Token 使用量,以便更好地制定预算。
- 介绍 bb7:本地 RAG 语音聊天机器人:bb7 是一款本地 RAG 增强语音聊天机器人,支持文档上传和上下文感知对话,且无需外部依赖。它集成了 Text-to-Speech (TTS) 以实现流畅交互,详见此处。
- 这一创新突出了在创建用户友好、具备离线能力的聊天机器人解决方案方面的进展。
- 测试用于数据分析的轻量级 API:展示了一个全新的数据分析 API,为 OpenAI Assistant 和 Code Interpreter 提供了一个更快速、更轻量级的替代方案,专门为数据分析和可视化而设计,详见此处。
- 它能生成 CSV 文件或 HTML 图表,强调简洁高效,无冗余细节。
OpenInterpreter Discord
-
Claude 命令中的 Anthropic 异常:用户报告了在使用最新的 Claude model 时出现的一系列 Anthropic errors 和 API 问题,特别是与命令
interpreter --model claude-3-5-sonnet-20240620相关的问题。- 一位用户发现了一个反复出现的 error,暗示这是一个影响多位用户的趋势。
-
Even Realities 增强 Open Interpreter:一位成员推荐将 Even Realities G1 眼镜作为 Open Interpreter 集成的潜在工具,强调了其 open-source commitment。
- 其他人讨论了其 hardware capabilities 并期待未来的插件支持。
-
Oasis AI:开创全 AI 生成游戏:团队发布了 Oasis,这是首个可玩的、实时的、开放世界 AI 模型,标志着向复杂交互环境迈出了一步。
- 玩家可以通过键盘输入与环境互动,展示了无需传统游戏引擎的实时游戏玩法。
-
Claude 3.5 Haiku 达到高性能:Claude 3.5 Haiku 现已在包括 Anthropic API 和 Google Cloud’s Vertex AI 在内的多个平台上可用,提供迄今为止最快、最智能的体验。
- 该模型在各种基准测试中超越了 Claude 3 Opus,同时保持了成本效益,正如这条推文中所分享的。
-
OpenInterpreter 为 Claude 3.5 进行优化:一个新的 pull request 引入了 Claude Haiku 3.5 的配置文件,由 MikeBirdTech 提交。
- 这些更新旨在增强在 OpenInterpreter 项目中的集成,反映了仓库的持续开发。
DSPy Discord
-
DSPy 全面支持 Vision:一位成员庆祝 Pull Request #1495 成功合并,该 PR 为 DSPy 增加了 Full Vision Support,标志着一个重要的里程碑。
- 这一刻期待已久,表达了对团队合作的赞赏。
-
Docling 文档处理工具:一位成员介绍了 Docling,这是一个文档处理库,可以将各种格式转换为结构化的 JSON/Markdown 输出,用于 DSPy 工作流。
- 他们强调了关键特性,包括对 scanned PDFs 的 OCR 支持,以及与 LlamaIndex 和 LangChain 的集成能力。
-
STORM 模块修改:一位成员建议改进 STORM module,特别是增强对目录(table of contents)的利用。
- 他们提议根据 TOC 逐节生成文章,并结合私有信息以增强输出。
-
在 Signature 中强制输出字段:一位成员询问如何在 signature 中强制要求一个输出字段返回现有特征,而不是生成新特征。
- 另一位成员通过概述一个正确返回特征作为输出一部分的函数提供了解决方案。
-
优化 Few-shot 示例:成员们讨论了在不修改 prompts 的情况下优化 few-shot examples,重点在于提高示例质量。
- 建议使用 BootstrapFewShot 或 BootstrapFewShotWithRandomSearch 优化器来实现这一目标。
tinygrad (George Hotz) Discord
-
WebGPU 在 tinygrad 中的未来集成:成员们讨论了 WebGPU 的就绪情况,并建议在准备就绪后立即实施。
- 一位成员提到,“当 WebGPU 准备就绪时,我们可以考虑这一点”。
-
Apache TVM 特性:Apache TVM 项目 tvm.apache.org 专注于跨多种硬件平台优化机器学习模型,提供模型编译和后端优化等功能。
- 成员们强调了它对 ONNX、Hailo 和 OpenVINO 等平台的支持。
-
在 tinygrad 中实现 MobileNetV2 的挑战:一位用户在实现 MobileNetV2 时遇到了问题,特别是优化器无法正确计算梯度。
- 社区参与了故障排除工作,并讨论了各种实验结果以解决该问题。
-
Fake PyTorch 后端开发:一位成员分享了他们的 ‘Fake PyTorch’ 封装器,该工具利用 tinygrad 作为后端,目前支持基础功能,但缺少高级功能。
- 他们征求了反馈,并对自己的开发方法表达了好奇。
-
Oasis AI 模型发布:Oasis 项目宣布发布一款开源实时 AI 模型,能够利用键盘输入生成可玩的视频游戏画面和交互。他们发布了 500M 参数模型的代码和权重,强调了其实时视频生成能力。
- 正如团队成员所讨论的,未来的计划旨在进一步提升性能。
OpenAccess AI Collective (axolotl) Discord
-
针对特定领域问答微调 Llama 3.1:一位成员正在寻找高质量的英文 instruct datasets 来微调 Meta Llama 3.1 8B,旨在集成特定领域的问答功能,相比 LoRA 方法更倾向于全量微调。
- 他们强调了通过微调实现性能最大化的目标,并指出了替代方法所面临的挑战。
-
解决微调中的灾难性遗忘问题:一位成员报告在微调模型时遇到了 catastrophic forgetting(灾难性遗忘),引发了对过程稳定性的担忧。
- 作为回应,另一位成员建议 RAG (Retrieval-Augmented Generation) 可能会为某些应用提供更有效的解决方案。
-
Granite 3.0 基准测试超越 Llama 3.1:Granite 3.0 被提议作为替代方案,其基准测试结果优于 Llama 3.1,并包含旨在防止遗忘的微调方法论。
- 此外,Granite 3.0 的 Apache 许可证也被强调,为开发者提供了更大的灵活性。
-
增强推理脚本并解决不匹配问题:成员们发现当前的推理脚本缺乏对 chat formats 的支持,仅处理纯文本并在生成过程中添加
begin_of_texttoken。- 这一设计缺陷导致了 mismatch with training(与训练不匹配),引发了关于潜在改进和更新 README 文档的讨论。
-
Aloe Beta 发布:先进的医疗保健 LLMs:Aloe Beta 发布,这是一套经过微调的开源医疗保健 LLMs 系列,标志着 AI 驱动的医疗解决方案的重大进展。详情请见此处。
- 开发过程涉及使用 axolotl 进行细致的 SFT phase(SFT 阶段),确保模型针对各种医疗相关任务进行了量身定制,团队成员对其潜在影响表示了极大的热情。
LAION Discord
-
32 个 CLS Tokens 增强稳定性:引入 32 个 CLS tokens 显著稳定了训练过程,提高了可靠性并增强了输出结果。
- 这一调整对训练一致性产生了明显影响,是模型性能提升方面值得关注的进展。
-
模糊的 Latent 下采样担忧:一名成员质疑了双线性插值 (bilinear interpolation) 在 latents 下采样中的适用性,指出结果看起来很模糊。
- 这一担忧凸显了当前下采样方法的潜在局限性,促使人们重新评估该技术的有效性。
-
标准化推理 API:Aphrodite、AI Horde 和 Koboldcpp 的开发者已就一项标准达成一致,以协助推理集成商识别 API,从而实现无缝集成。
- 新标准已在 AI Horde 等平台上上线,目前正在努力引入更多 API 并鼓励开发者之间的协作。
-
RAR 图像生成器刷新 FID 记录:RAR 图像生成器 在 ImageNet-256 基准测试中实现了 1.48 的 FID 分数,展示了卓越的性能。
- 通过利用随机性退火策略,RAR 在不增加额外成本的情况下,表现优于以往的自回归图像生成器。
-
位置嵌入打乱的复杂性:有人提议在训练开始时打乱位置嵌入 (position embeddings),并逐渐将这种效果在结束时降低到 0%。
- 尽管具有潜力,但一名成员指出,实现这种打乱比最初预想的更复杂,反映了优化嵌入策略所面临的挑战。
LLM Agents (Berkeley MOOC) Discord
-
LLM Agents Hackathon 设置截止日期:提醒各团队在 11 月 4 日周一结束前设置好 OpenAI API 和 Lambda Labs 访问权限,以免影响资源获取;可以通过此表单提交。
- 尽早设置 API 可以在下周获得来自 OpenAI 的额度,确保在整个黑客松期间顺利参与并访问 Lambda 推理端点。
-
Jim Fan 展示 Project GR00T:Jim Fan 将在 PST 时间下午 3:00 的直播中展示 Project GR00T,这是 NVIDIA 为通用机器人 AI 大脑发起的项目。
- 作为 GEAR 的研究负责人,他强调在各种环境下开发具有通用能力的 AI Agents。
-
黑客松组队:寻求 LLM Agents Hackathon 合作机会的参与者可以通过此团队报名表进行申请,并概述创新型基于 LLM 的 Agents 的目标。
- 该表单便于团队申请,鼓励组建专注于创建高级 LLM Agents 的小组。
-
Jim Fan 的专业知识与成就:Jim Fan 博士毕业于斯坦福视觉实验室 (Stanford Vision Lab),因其在机器人多模态模型和擅长 Minecraft 的 AI Agents 方面的研究,荣获 NeurIPS 2022 杰出论文奖。
- 他的影响力工作曾被《纽约时报》和《麻省理工科技评论》等主流媒体报道。
Cohere Discord
-
模拟 ChatGPT 的浏览机制:研发部门的一位成员正在探索通过跟踪搜索词和结果来手动模拟 ChatGPT 的浏览,旨在分析 SEO 影响以及模型高效过滤和排序多达 100 多个结果的能力。
- 该计划旨在将 ChatGPT 的搜索行为与人类搜索方法进行比较,以增强对 AI 驱动的信息检索的理解。
-
聊天机器人挑战传统浏览器:讨论强调了 ChatGPT 等聊天机器人取代传统 Web 浏览器的潜力,并承认预测此类技术转变的难度。
- 一位参与者引用了过去的技术预测(如 视频通话 的演变),以说明未来进步的不可预测性。
-
增强现实改变信息获取方式:一位成员提出,增强现实可以通过提供持续更新来彻底改变信息获取,超越当前对 无浏览器环境 的预期。
- 这一观点扩展了对话,涵盖了潜在的 变革性技术,强调了与信息交互的新方法。
-
Cohere API 查询重定向:一位成员建议不要在 Cohere API 频道发布一般性问题,而是将其引导至适当的 API 相关查询讨论空间。
- 另一位成员幽默地承认了错误,指出用户中广泛存在的 AI 兴趣,并承诺会妥善引导未来的问题。
Torchtune Discord
-
Torchtune 支持分布式 Checkpointing:一位成员询问 Torchtune 中是否有与 DeepSpeed 的
stage3_gather_16bit_weights_on_model_save等效的功能,以解决多节点微调过程中的问题。- 澄清了将此标志设置为 false 有助于 分布式/分片 Checkpointing,允许每个 rank 保存自己的分片。
-
Llama 90B 集成到 Torchtune:分享了一个将 Llama 90B 集成到 Torchtune 的 Pull Request,旨在解决 Checkpointing 相关的 Bug。
- PR #1880 详细说明了集成过程中与 Checkpointing 相关的增强功能。
-
澄清梯度范数裁剪 (Gradient Norm Clipping):成员们讨论了 Torchtune 中梯度范数的正确计算方法,强调需要对所有参数梯度的 L2 范数进行归约 (reduction)。
- 在下一次迭代中可能会裁剪梯度范数,但这将改变原始的梯度裁剪逻辑。
-
配置中重复的 ‘compile’ 键导致失败:在 llama3_1/8B_full.yaml 中发现了一个重复的
compile键,导致运行失败。- 目前尚不确定其他配置文件是否存在类似的重复键问题。
-
ForwardKLLoss 实际上计算的是交叉熵 (Cross-Entropy):Torchtune 中的 ForwardKLLoss 计算的是交叉熵而非预期的 KL 散度 (KL-divergence),需要调整预期。
- 这种区别至关重要,因为由于常数项的存在,优化 KL 散度实际上等同于优化交叉熵。
Alignment Lab AI Discord
-
Aphrodite 增加实验性 Windows 支持:Aphrodite 现在处于实验阶段支持 Windows,实现了针对 NVIDIA GPU 优化的高吞吐量本地 AI。有关设置详情,请参阅安装指南。
- 此外,已确认支持 AMD 和 Intel 计算,尽管 Windows 支持仍处于未测试状态。感谢 AlpinDale 带头开展 Windows 实施工作。
-
LLM 驱动自动打补丁创新:一篇关于自愈代码的新博客文章讨论了 LLM 如何在自动修复漏洞软件中发挥关键作用,标志着 2024 年是这一进步的关键一年。
- 作者详细阐述了解决自动打补丁的六种方法,其中两种已作为产品提供,四种仍处于研究阶段,突显了实际解决方案与持续创新之间的融合。
-
LLM Podcast 探讨自愈软件:LLM Podcast 专题讨论了自愈代码博客文章,为软件自愈技术提供了对话式的见解。
- 听众可以在 Spotify 和 Apple Podcast 上收听该播客,以便以音频形式获取内容。
MLOps @Chipro Discord
-
LoG 会议落地德里:Learning on Graphs (LoG) 会议将于 2024 年 11 月 26 日至 29 日在新德里举行,重点关注图机器学习的进展。首届南亚分会由 IIT Delhi 和 Mastercard 主办,更多详情请点击此处。
- 该会议旨在连接图学习领域的创新思想家和行业专业人士,鼓励来自计算机科学、生物学和社会科学等不同领域的参与。
-
LoG 2024 中的图机器学习:LoG 2024 非常强调图机器学习,展示了该领域的最新进展。与会者可以在官方网站上找到有关会议的更多信息。
- 该活动旨在促进跨学科讨论,推动机器学习、生物学和社会科学专家之间的合作。
-
LoG 2024 本地聚会:LoG 社区正在组织一个本地小型会议网络,以促进不同地理区域的讨论和合作。LoG 2024 本地聚会征集目前已开放,旨在增强主活动期间的社交体验。
- 这些本地聚会旨在将来自相似地区的参与者聚集在一起,促进社区参与和共享学习机会。
-
LoG 社区资源:LoG 2024 的参与者可以加入 Slack 上的会议社区,并在 Twitter 上关注更新。此外,往届会议的录音和材料可在 YouTube 上获取。
- 这些资源确保与会者能够持续获得宝贵材料,并在会议日期之外与社区互动。
Gorilla LLM (Berkeley Function Calling) Discord
-
基准测试所需的函数定义:一名成员正在对一种基于检索的方法进行 function calling 基准测试,并正在寻求一系列可用的 functions 及其 definitions 以进行索引。
- 他们特别提到,将这些信息按测试类别组织会非常有帮助。
-
结构化集合增强基准测试:讨论强调了对结构化函数定义集合的需求,以辅助 function calling 基准测试。
- 按测试类别组织信息将提高从事类似工作的工程师的可访问性和易用性。
LLM Finetuning (Hamel + Dan) Discord 没有新消息。如果该频道长时间没有动静,请告知我们,我们将将其移除。
Mozilla AI Discord 没有新消息。
AI21 Labs (Jamba) Discord 没有新消息。
第 2 部分:按频道详细摘要和链接
完整的频道细分内容已因邮件长度限制而截断。
如果您喜欢 AInews,请分享给朋友!预先感谢!